Riichi Mahjong LLM
Table of Contents
Teaching LLMs to Play Mahjong
Abstract
Riichi Mahjong hits the sweetspot for LLM-as-game-playing-agent experimentation. It has plentiful high-level data, it's well described as text, it's easily described in a markovian way, and it doesn't have lots of easily available engines for it already. In this work I teach an LLM how to get good at mahjong. The goal is threefold: first, to train a language model to play the game properly; second, to lay the foundation for a mahjong model which can explain why moves are good or bad; third, to reproduce some interesting papers I read recently on a novel environment.
Introduction and Related Work
Lots of work has been done on training LLMs to perform well at games, mostly popular traditional ones like Chess. I won't go into too much detail about everything out there (since this is a get-hands-dirty holiday break project) but two papers are standouts motivating my approach here.
Causal Masking on Spatial Data: An Information-Theoretic Case for Learning Spatial Datasets with Unimodal Language Models is the primary paper we are attempting to reproduce in this post. They trained a 1.3B LLM on chess positions annotated with Stockfish. They do 200k steps at batch size 128, gradient accumulation 32 for an effective batch size of 4096 samples per step. At 200k steps that's about 820 million positions, if my napkin math checks out. The model achieved a measured Elo of ~2600, matching roughly grandmaster strength1.

I was really impressed by this paper! A 7B parameter model distilling stockfish this well would have been pretty mundane, but a 1.3B model being so successful opened up a world of possibilities, since fine-tuning a model of this size is not really a huge lift for somebody with the right expertise. They also point to Ruoss et al 2024 which trained a smaller transformer (270M) from scratch on a much larger dataset to get an even better result (2895 rating)2.
Mixing Expert Knowledge: Bring Human Thoughts Back To the Game of Go trained a 7B and 32B model on Go by distilling the moves from a strong RL model upon a language model cold-started with human annotations of Go positions. This model reached 9d strength, which is very strong (but human level, compared to superhuman RL bots which crushed even the very best players). Critically, however, these models were able to provide actual reasoning for why the moves it selected were good or bad.
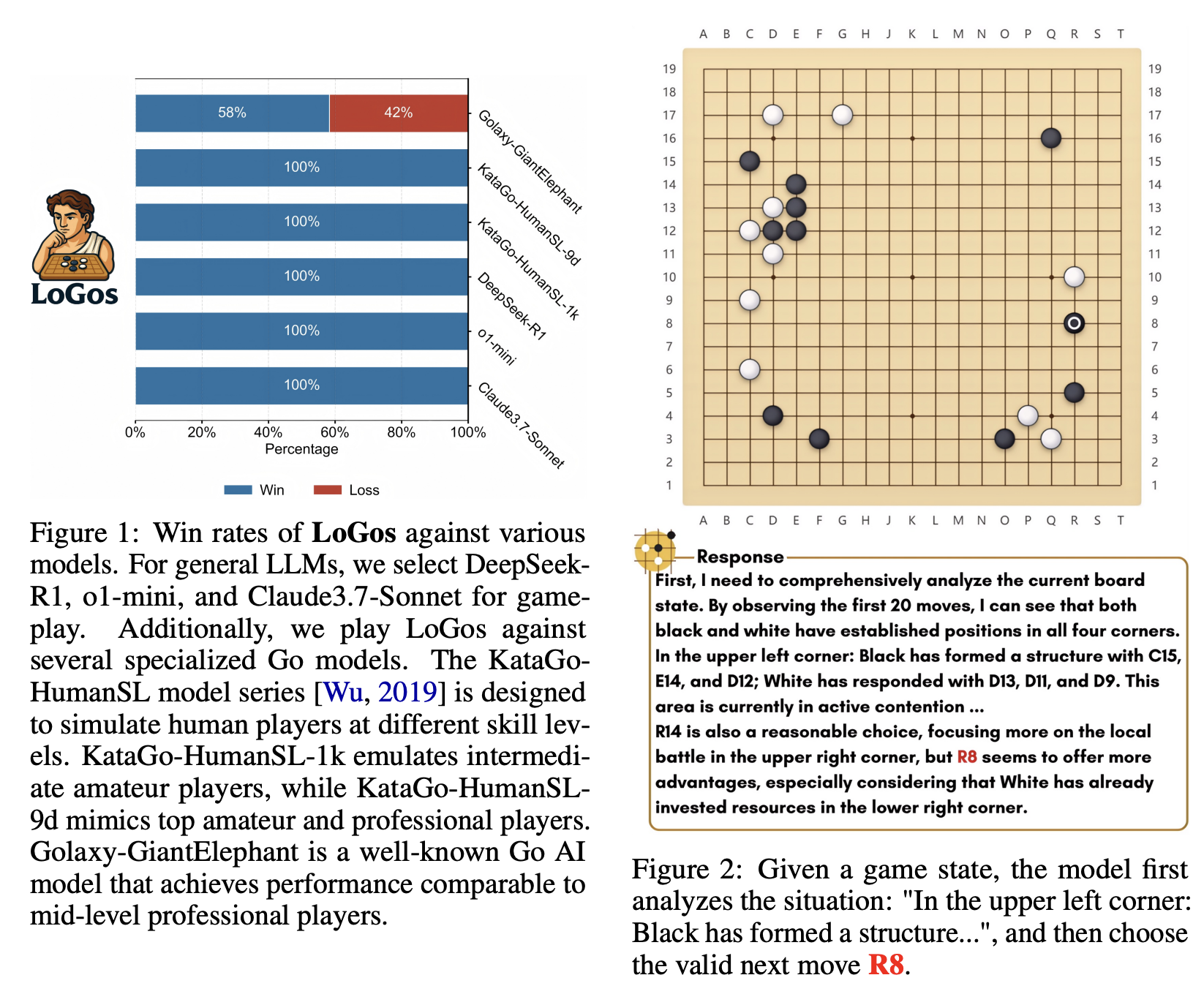
I saw this paper and promptly flipped out at the implications of it, it was by far my favorite result from NeurIPS 2025. Anybody who has tried to analyze a board game with an engine has lots of experience not understanding why they should have done move X instead of move Y. This paper points to a future where you could just ask! There's a lot of interesting applications this opens up if the result holds for other settings, obviously making it relevant as a north star for our mahjong project.
Gathering Data
Ample data from strong players is freely available, since mahjong players are playing mahjong roughly all the time. Amber from Path of Houou has posted a large database of five years' worth of Tenhou replays from strong players, which is a useful starting point for training something like this. Each year has about 250 thousand hanchans in it, so five years of games should result in roughly 1.25 million hanchans, which likely result in something like 800 million positions.
Previous examples mentioned will distill the policy of a very strong model (e.g. stockfish) by annotating every position with the oracle's top move. There exist strong RL-powered models for riichi mahjong like Mortal or MAKA, but these are not freely available to download, and do not offer batch processing for large quantities of games. However, it's possible we don't need to annotate games via the oracle at all.
In Transcendence: Generative Models Can Outperform The Experts That Train Them they showed that models trained on low level chess games will produce a model which is stronger than any individual player. This is because bad moves can be framed as noise; on average bad players still play reasonable moves, and have decorrelated errors from one another3. Since Deep Learning is Robust to Massive Label Noise, the resulting model is strong even when all the annotators are weak. Similar experiments were done even way back before chess computers were ubiquitous – Garry Kasparov vs The World was one such game where thousands of players voted on what move to play against world champion Garry Kasparov, which produced an interesting and competitive game despite the average voter being way, way weaker than Kasparov.
Ergo, we will be training the model to be a pure imitation learning model, for now. This should simplify the workflow substantially at the starting phase of this project, since it's now just framed as a straightforward supervised learning problem the same way any other SFT workflow would be. It's likely that we won't get superhuman results with this approach, but that's just fine, that's not necessarily the goal.
On top of being performant at the game, a desirable behavior of the model is the ability to solve "2d problems" (i.e. positions without context from the other players) as well as "3d ones". Many training tools and improvement resources are framed this way, since a 2d example is sufficient for capturing lots of important concepts like tile efficiency, block identification, maximizing expected value, and so on. We set aside a portion of the data which masks the discards and other players, to enable the model to answer questions like "what do you discard from this hand, in general?"
Training
To actually train this, since we have a relative lack of compute resources, I'll be using Tinker from Thinking Machines. This lab provides streamlined resources for finetuning language models of various sizes using Low Rank Adaptation (LoRA). Tinker is nice since it will allow us to focus on data and training loop, rather than needing to fiddle with infrastructure. There's some concern with using LoRA over full finetuning, but they have a blogpost outlining that LoRA is close enough in performance to full finetuning for post-training applications.
We choose Llama 3.2 1.3B as the primary model for this experiment, since it's inexpensive, fast, and was shown to be highly performant for chess in Causal Masking on Spatial Data.
Napkin Test I
As a quick napkin test, I finetuned llama-3.2-1B on ~500 positions and provided it with the following problem (one of my favorites, from G. Uzaku's Gold Book).

Dealer seat, 1m 2m 3m 3m 4m 5m 6m 7m 9m 3p 3p 7s 8s 9s, with 8s as the dora.
This is a nice little test of a beginning player's grasp of the concepts. This hand is now in tenpai three different ways.
- You can discard 6m and riichi for riichi dora 1 as dealer, waiting on the four 7m tiles.
- You can discard 3m and riichi for riichi closed ittsu dora 1 as dealer, waiting on the four 7m tiles.
- You can discard 9m and riichi for riichi pinfu dora 1 as dealer, waiting on the 10 remaining tiles of 2m/5m/8m.
The 6m is obviously worse than the other options, but an easy mistake to make is to discard the 3m here. Ittsu (pure straight in one suit) is flashy and pretty, and a four tile wait for a hand this big is pretty good4. But discarding the 9 gives you pinfu (i.e. destroying ittsu only loses 1 han, not 2), lets you win with way more tiles (10 > 4), and can win with red 5 for an extra han.
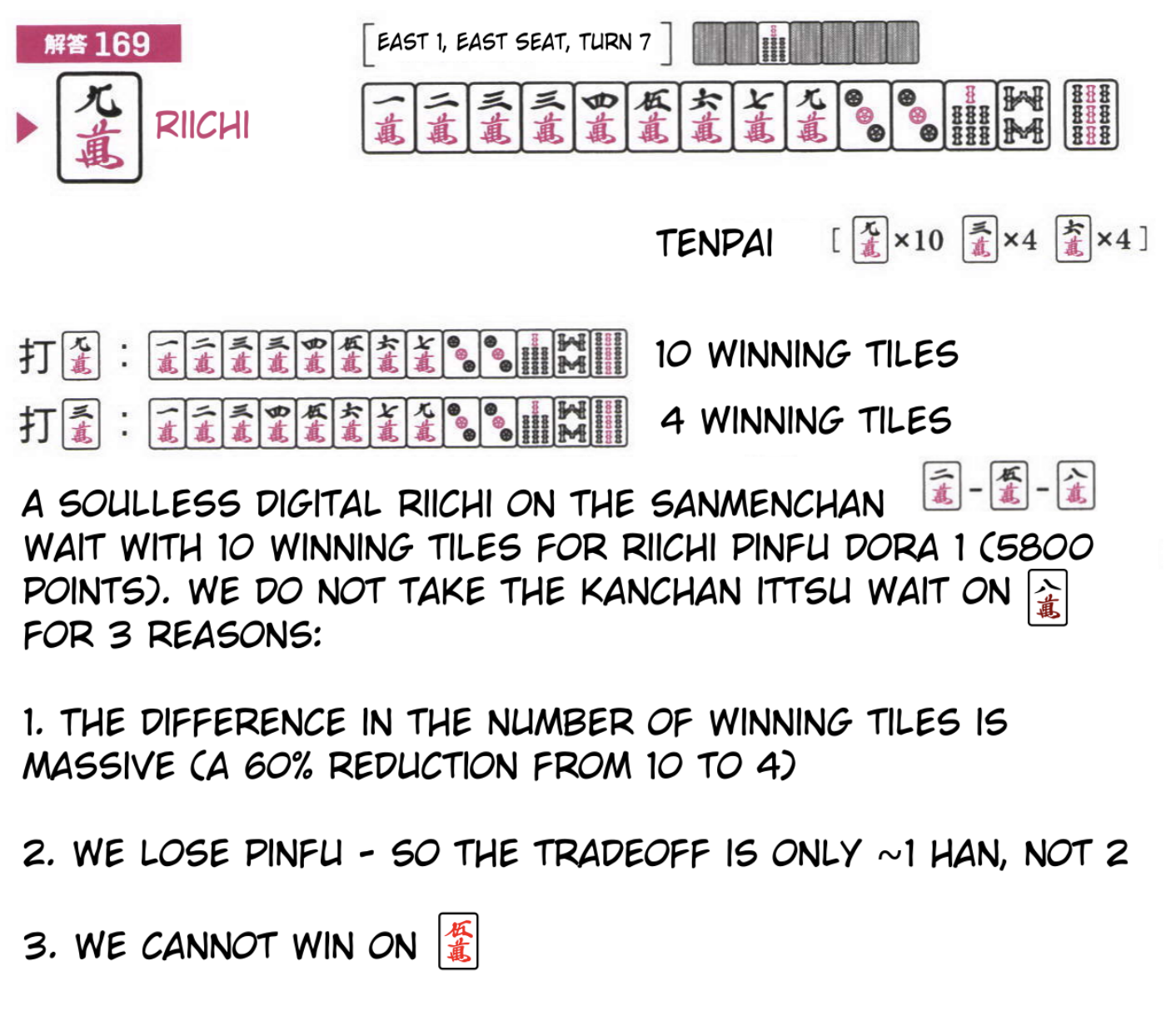
The expected value is much better for the 9m. With just 500 examples I was happy to see the model understand that discarding the 3m was a potential candidate move, even if it's not quite correct (likely leveraging some prior knowledge about mahjong from pretraining, another nice advantage of using LLMs for a problem like this). Definitely a far cry from what we really want, but at this stage I was expecting "picks a legal move" to be a bigger hurdle than it ended up being.

With this I was confident enough to proceed with a larger training run.
Training Run I
For the first "real" training run I wanted to scale up to all the games in the 2016 database. This was about 250k hanchans, so it was a lot of data compared to the napkin test. This was roughly one fifth of my available data so I thought it was a good kickstart for something like Tinker which is capacity constrained by using LoRA anyways5. It was a minor annoyance trying to scale this data up this much while keeping under memory constraints, since I couldn't just dump everything in an array and write it to a file at the end anymore6.
Once we put everything together ended up with 169,379,861 total training examples. 138,798,623 3D examples, and 30,581,238 2D examples. This results in something like 40 billion tokens7. This was a bit more than I was initially expecting. Partway through putting all the data together I realized I probably didn't have enough compute credits to complete the project even with just this much data. Even fully matching the methodology from the Causal Masking paper would require just 9.6 million examples.
So I decided to subsample to target roughly 1 billion tokens instead. This would be theoretically under my toy budget (~$150)8 per tinker pricing for Llama 3.2 1B, and would still give us over 3 million examples to work with. We can proceed with the knowledge that with the appropriate resources we could scale to nearly a billion training examples, for something like 250 billion tokens just spent on imitation learning for riichi mahjong9.
The training details were as follows.
| Parameter | Value |
|---|---|
| LoRA rank | 128 |
| Learning rate | 4.9e-4 |
| LR schedule | linear |
| Batch size | min(128, numExamples // 4) |
| Max sequence length | 2048 |
| Training Set Size | 3.7M Examples |
| Number of epochs | 1 |
| Eval Set Size | 10k Examples |
| Eval every | 1500 steps |
I encountered an amusing bug when kicking this off. When I launched the script, I got the following.
Found 3702681 training examples in /Users/ebanatt/Documents/code/mahjong-llm/train_data.jsonl
After hanging here for well over an hour, I killed the process to see where it was stuck, thinking I could add print statements or tqdm or something, to see the progress. Instead it told me it was stuck at user input, meaning I needed to do something. With some digging through the source I determined it was supposed to ask me if I wanted to delete, resume, or exit, since previous training output already existed. Whoops! I just typed "delete" and it started training pretty much right away.
Found 3702681 training examples in /Users/ebanatt/Documents/code/mahjong-llm/train_data.jsonl delete Log directory /Users/ebanatt/Documents/code/mahjong-llm/training_output already exists. What do you want to do? [delete, resume, exit]: tinker_cookbook.utils.ml_log:477 [INFO] Logging to: /Users/ebanatt/Documents/code/mahjong-llm/training_output
Training on all this data took about seven hours10. It definitely did appear to learn based on the loss curves. It trained on 1.14B tokens, which cost $102.92 USD in total.
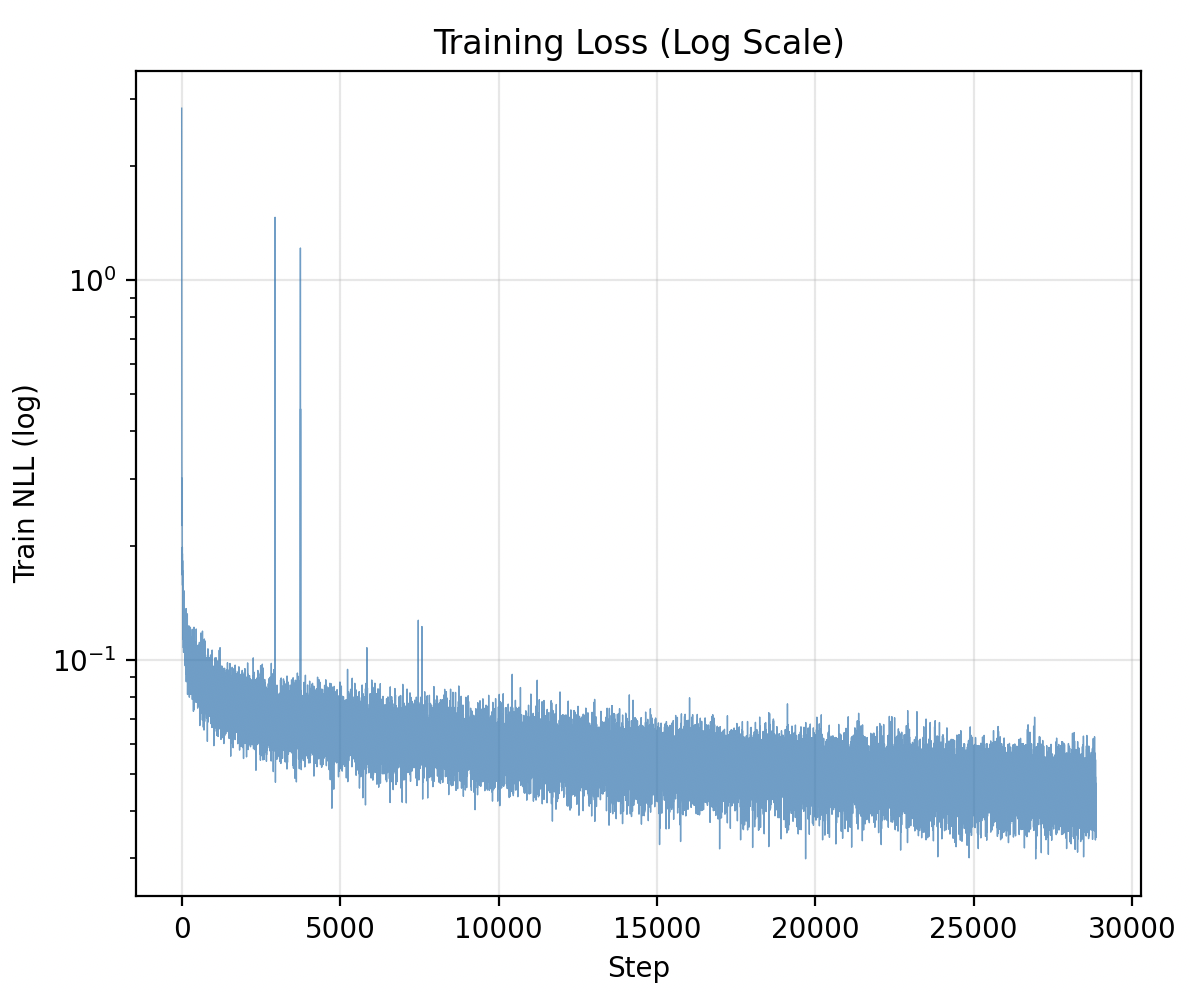
Napkin Test II
Running the same test after training, we can see that it picks the 9 man this time! We have successfully defeated the allure of ittsu, demonstrating that we've learned something tangible about how to play riichi mahjong.

I'll update this section with more napkin tests as I perform them upon our trained model. But, hooray, we did it!
Extending to Reasoning Data
[Update 1/30/26]
After gathering lots more mahjong data for another project, I had a much cleaner and more comprehensive data pipeline which could help with this project. As a result, I took an initial stab at making the model capable of talking about its decisions.
System Prompt: I had read a bit about how this reasoning mode works in studying agentic models for the Understanding Agentic LLMs post. I knew that for instruction data a simple "reasoning: off" type flag is pretty effective for training these "hybrid" type models which are optionally capable of reasoning. As a result, I unified all the prompting so that I could simply toggle "Reasoning: On" vs "Reasoning: Off" in the training examples.
2D Reasoning Data: I gathered about 300 examples of 2D "What Would You Discard" problems from various sources, and painstakingly made these verifiably correct. These provide a lot of actual information regarding what explanations should look like, which is great.
Synthetic 3D Reasoning Data: I created a pipeline that allowed me to create some simple reasoning examples with the full 3D Byako. This was mostly some very simple stuff: asking how much a winning hand was worth, what yakus were present, how many fu it used, what the shanten of the hand is, and so on.
Napkin Test III
I got a small set of data for training and went ahead with another napkin test training run. This was obviously not on the scale necessary to make the model work properly. However, we already got some promising results even with just this. On our same discard example, we still correctly throw the 9 of characters (although we do not riichi), and we only provide reasoning when asked for. Some nice progress!
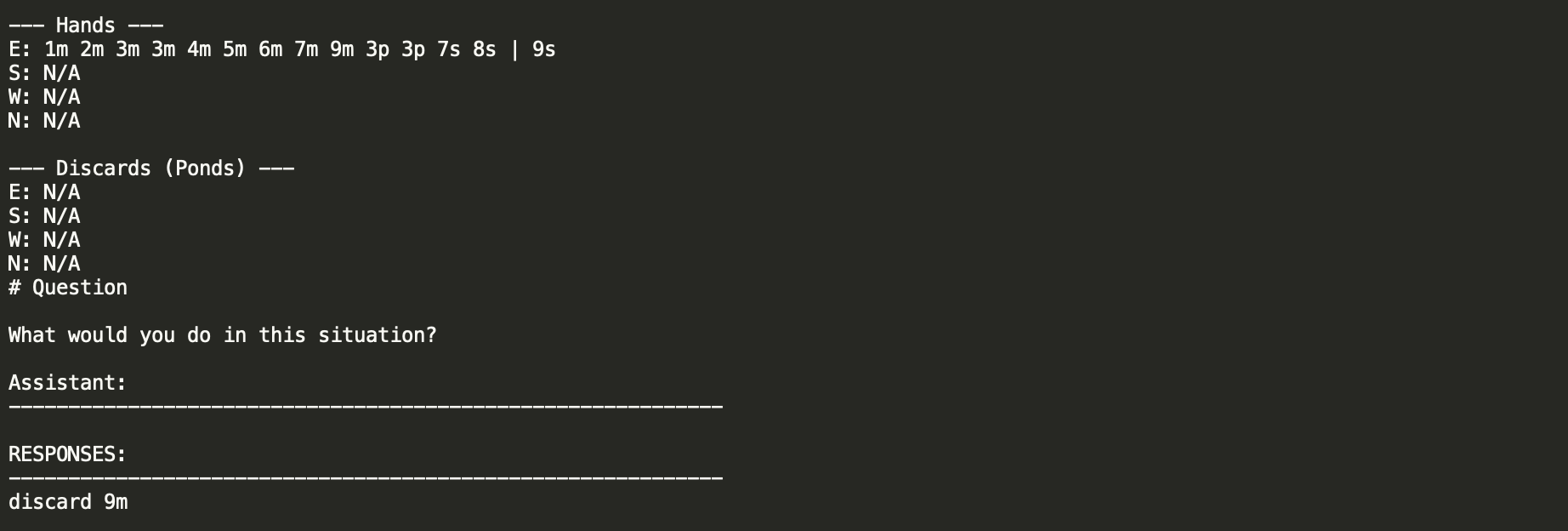
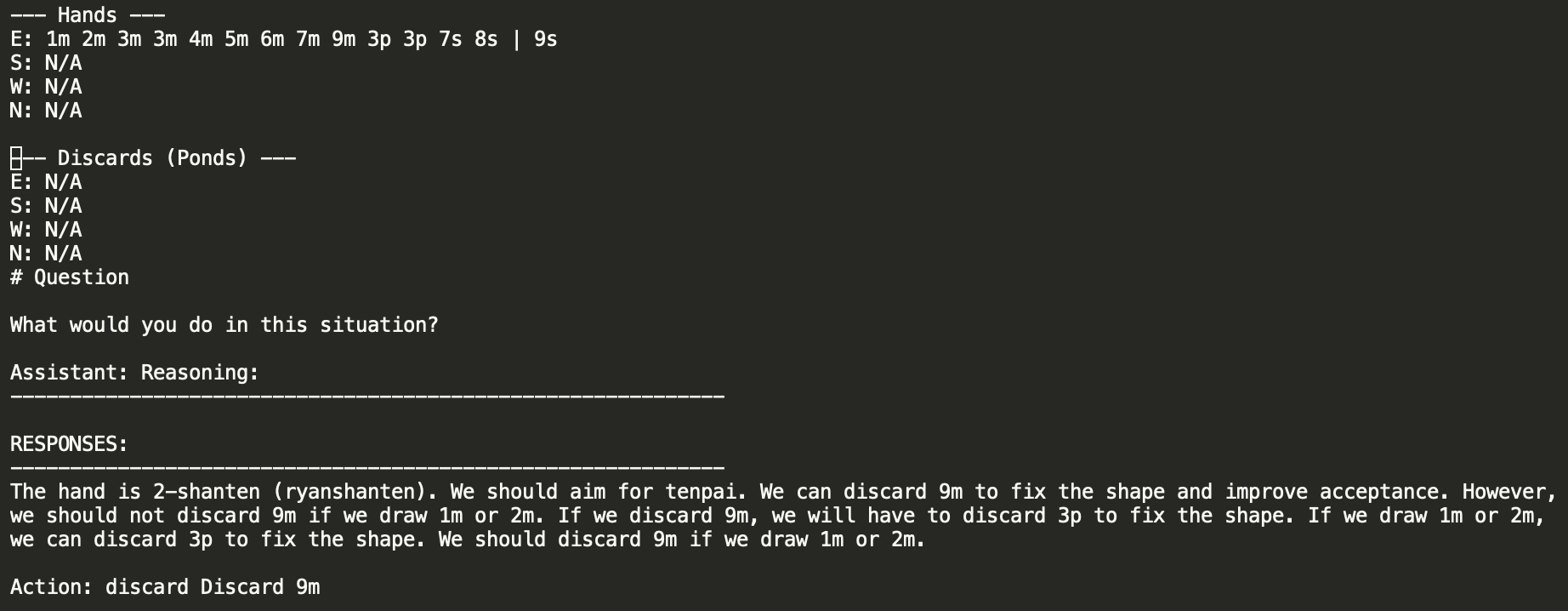
We've already shown some nice justification for the shanten synthetic data here: we clearly do not understand tenpai yet, even if we can pick the correct tile from a lineup. But we have a nice yardstick representing our progress at making something which is more "coaching shaped" than our previous training run.
Future Work
Lots of work left to be done with this. Scaling up training to something larger or using more data is a given. The methodology still has juice left judging from the loss curves, and as mentioned we only used about 2% of 1/5th of the data11. With more spend we could definitely see even better results.
Likewise, we have to do some benchmarking for this model. I'll get around to this eventually. Performance on the held out test set we used saturated really fast in training despite the training curves, so we probably need to construct a dataset which only uses interesting examples rather than a random set of discards (the vast majority of which are probably very straightforwards.)
Finally, I'd like to make some progress towards getting it to explain its decisions. This might be a tough ask for something as small as 1.3B parameters, but now that we have a working pipeline we can focus on more productive things like assembling cold start reasoning data, generating synthetic data, reinforcement learning, and so on.
[Update 1/30/26]
With some improved data pipelining, we've made sure that we have everything working nicely: red fives, closed kans, riichis, everything was much cleaner in this second run. Likewise, we have the groundwork laid for allowing the model to actually explain the decisions.
This was a good second step – we have the pipeline in place now, and we just have to scale up from here to see where we land. Adding reinforcement learning as the final pipeline step seems like a potential next step after that.
Footnotes:
The Elo estimation from this paper is hazy since it uses winrate against various stockfish levels instead of human opponents. However, it's definitely still very strong. I was ~1600 blitz rating when I was an active chess player and it's tough for me to beat stockfish level 5-6.
This is definitely noteworthy but decidedly adjacent; the ultimate goal of our mahjong project here isn't to produce a strong riichi mahjong model per se (Mortal and others already do that), it's to train a language model which under the right circumstances could explain its decisions. We need something generally capable for that, which is why we highlight the language model despite its worse performance.
This is obviously not always true. There are lots of positions where beginner players are all going to miss the critical move. But low level players will, for example, regularly make insane moves where they do not see their queen can be immediately captured by a knight on the next move. These are the types of errors which are trivially filtered through averaging.
Riichi Book I is a good resource for judgment like this
I have five years of data and it's very possible that performance will saturate far below the use of all of my data regardless, so I didn't want to get ahead of myself.
At this stage it was simple enough to just write as we go to a file, but it ended up being very very large (~125GB compared to the db of games itself only being 1.6GB). If I scale up past this I'll need to start considering using protobuf or some other efficient mechanism for serializing data.
napkin math at ~267 characters per example ~3.2 chars per token ~160M examples. Maybe off base, but probably too large.
They gave me some starter credits when I got off the beta waitlist, so I'm just trying to spend those for this project to determine my opinion.
this would be pretty insane, but probably a complete waste of resources. This would be like a quarter of the tokens used to train starcoder but literally only for human-level mahjong play.
Really fast, all things considered. I know in the Causal Masking paper they say they trained for two weeks on two A100 gpus for 200k steps, so an equivalent number of steps here would take just under two days. I suppose this is probably due to LoRA differences, but it sure is nice to not have to think of the infrastructure concerns when running experiments. In the future it probably would be useful to directly rent some GPUs by the hour and do a project actually confronting all of this infra stuff, but it's good that the skills can be decoupled a little bit.
That is, we only used the 2016 db, and we only subsampled 2% of that data.